Resolving the AI Copyright Debate through Open Source Licensing: Classifying AI as Derivative Works
A proposed solution for all parties ...

Runs a Low Code UI test automation startup ( https://uilicious.com/ ) and is part of the GPUJS team ( https://gpu.rocks/ )
Hot-takes/Views are my own
What are the scales of justice, for the artist, and the AI ?
If we don't sort out the legal issues surrounding AI-generated content properly, it could have serious implications for the future of thousands of jobs.
It's better to address these issues now rather than later, as the potential damage grows with the increased use of AI across all industries.
Throughout this article, you will see the term "works" frequently used to refer to any content to which copyright can be assigned, including images, artworks, and written text. To avoid confusion, the user of the AI model will be referred to as the "human operator", this is separate from the “creator” of the AI model itself.
For the purposes of this article, we will primarily be discussing the legal issues surrounding AI art generators, as they are currently at the forefront of this debate. However, the proposed solution discussed here is applicable to all AI models, including text-based ones.

A crash course on the AI copyright debate (and a disclaimer)
To oversimplify an extremely complicated topic that could fill multiple legal essays on its own, the current legal status of AI-generated content is undecided, with lawyers and members of the public advocating for either side.
One high-profile case (which is not yet finalized) is the "US Copyright Office" going back and forth on the copyright status of an AI-generated comic (link here)
At its core, the AI copyright debate revolves around three major questions:
Is it permissible (possibly under the concept of fair use) to use copyrighted materials to train an AI?
Can AI-generated works be copyrighted?
If so, can an AI model be co-assigned copyright of a generated work (e.g. an artwork) along with its "human operator"?
In general, these are the major arguments for AI.
Proposition 1: AI learns and creates (words, music, art, etc) like a human
Proposition 2: AI is just a tool
With the following 3 major opposition
Opposition 1: Only "real" humans are eligible for copyright
Opposition 2: Fair use is not automatic and is evaluated on a case-by-case basis
Opposition 3: Lack of consent, from data sources used in the dataset
There are many additional arguments for and against AI that have been made by both sides, but they are not included here because they are either not as significant as the key points or they are based on ethical considerations rather than existing legal codes.
For example, one notable argument that was left out: is the "for progress" proposition. On how AI should be allowed to learn from copyright materials to encourage progress in society, and that resisting such progress is harmful to society. This is an argument based on ethical and societal considerations and not an existing legal code.
As I am skimming the details of the debate, if you want a more in-depth read, you can consider theverge article - The scary truth about AI copyright is nobody knows what will happen next
Finally, to state the obvious, I am not your lawyer, and the following is not legal advice. Also, copyright laws differ drastically from country to country (Japan, for example, does not fully recognize fair use).
Now with all of that, out of the way ...

A Proposal to Classify AI-Generated Content and AI Models as Derivative Works with Attribution*
- with various limitations depending on the process used in each step
More specifically, the following sequence is proposed:
Dataset as a collection of work, from its individual data sources*
AI Model as derivative work, from the dataset, together with the AI model creator
- If an AI model is used to train another AI model (instead of a dataset), it is classified as a derivative of the base model, its training data, and its trainer model.
AI Output as derivative work, from the AI model, together with the "human operator" who provided a "prompt/instruction"*
This proposal allows us to divide the copyright problem into distinct steps and rely on existing legal frameworks and case laws, particularly the legal framework revolving around "Collaborative authorship" of open-source code. It also helps to answer the three questions distinctively:
In this framework, it would also allow answering the 3 questions distinctively.
Is it permissible, under fair use, to use copyrighted materials to train an AI?
- No, by default, unless it allows derivative work*
Can generated works be copyrighted?
- Yes*
If so, can an AI model be co-assigned copyright of a generated work (e.g. artworks), together with its human author (user of the AI)?
- Kind of. It would be attributed to.*
This proposal avoids being stuck in the debate of whether an AI performs the creation of work "like a living being." It also helps to create a clear path for all parties involved in a fair way:
For Artists
It gives them control over their own unique brand name and art style, allowing them to commercialize it where possible
It does not stop AI from being used to generate artwork in known older art styles
For AI Model Creators
- It provides a legal framework for them to create and commercialize AI models safely
For Human Operators
It allows them to generate AI artwork
It allows them to potentially commercialize such artworks for their own personal or commercial uses.
Understanding Permissive License (Usually with Attribution Clause)
One major factor that is often overlooked in the debate is how copyright is not binary, and how permissive licenses lie between full restrictive copyright and no copyright.
This proposal intends to take into account how permissive licenses are treated in the process and intends to use such licenses as a means to navigate the legal debate.
Because permissive licenses have been a hallmark in the open-source copyright movement for software coding (e.g. MIT license), this will help lay the groundwork for the proposed approach to existing case laws. (The list of open-source licenses can be found here.)
Outside of the software industry, the Creative Commons is its most prominent variant, with over 2 billion works tracked in circulation.
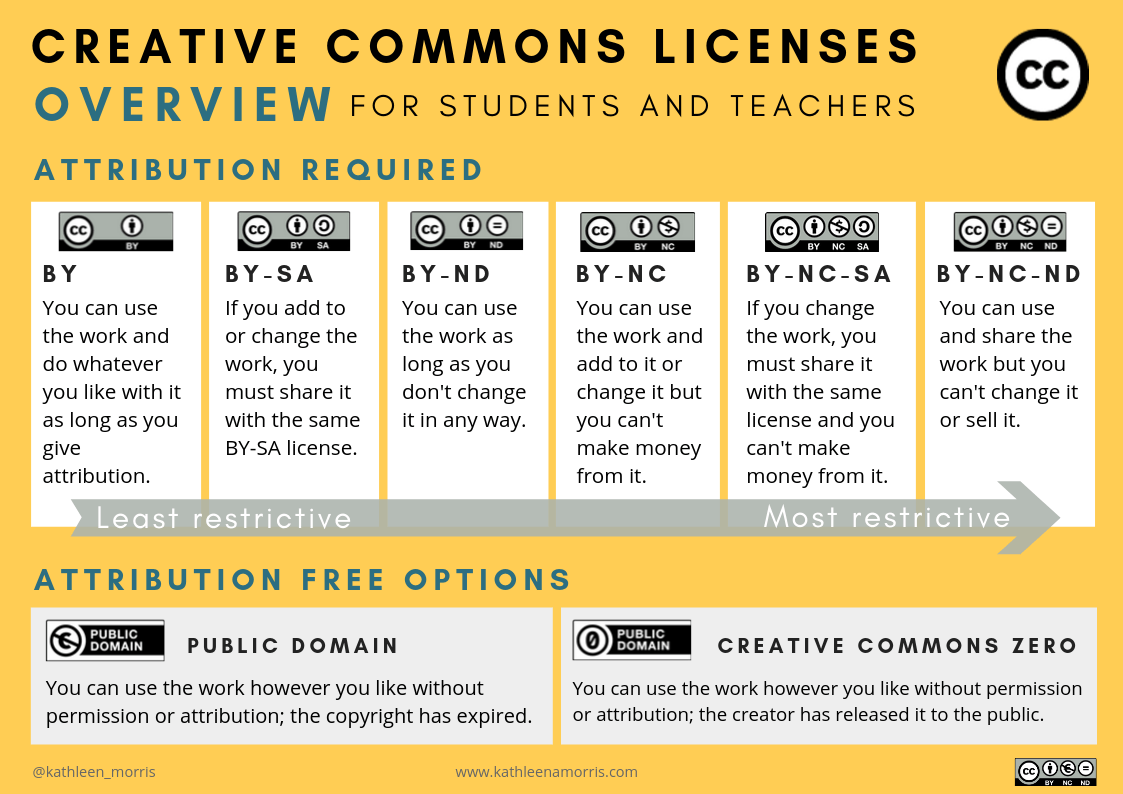
Broadly speaking, permissive licenses are used within three major categories:
1. Content that Cannot be Used: Share Alike, and No-Derivatives
No Derivatives is as obvious as it gets, No Derivatives.
- Creative Commons
BY-NDandBY-NC-ND
- Creative Commons
Share Alike, or CopyLeft licenses, require the existing license to be copied over into the license of the derivative work. While technically this is possible within smaller focused datasets, for practical purposes this should be avoided due to the logical challenge when merging multiple "CopyLeft" licenses.
- Creative Commons
BY-SAandBY-NC-SA, for software code, an example would be theGPL/AGPL/LGPLlicenses.
- Creative Commons
It is worth reminding the tech bros that no consent (to make derivatives) means no consent.
2. Content that Can be Used: Typically with Attribution
Derivative and distribution is allowed with attribution
- Creative Commons
BY, for software, an example would be theMITlicense
- Creative Commons
Derivative and distribution is allowed even without attribution
- Works in the Public Domain, or licensed under Creative Commons Zero
3. Content that Can be Used: For Non-Commercial Use Cases
Distribution and derivative with attribution, limited to non-commercial use.
- Creative Commons
BY-NC
- Creative Commons
Placing an early prediction, there will be a derivative of the Creative Commons license which specifically prohibits the usage with a dataset or AI training.
Maybe
BY-NADD(No AI nor Dataset Derivatives)

Important Note: Limitations MUST be Carried Forward
Permissive licenses are typically written in a way that enforces derivative works, and any collections including their work, or its distribution, to have the same limitation (attribution, non-commercial requirements).
Measures must be taken to ensure the same limitations apply to the dataset, AI model, and their generated content.
Failure to do so would break the current proposal, due to the loopholes that will allow commercial companies to fund the creation of public datasets under "fair use" only to eventually use them commercially.
For example:
LAION.AI - was commissioned to build and open-source a "Non-Commercial" dataset
Stability.ai - built an AI model, based on the LAION.AI dataset, without the "Non-Commercial" restriction, and released it to the public
Dreambooth.ai, and countless other commercial AI art generators - used the model to build their paid commercial AI art generator.
The end result is, despite starting out in a way that "does not create a competing product," due to its open-source nature, it ends up as a tool that can be used in commercial settings to replace specific living artists identified by their name, who had their images scraped within the dataset without consent.
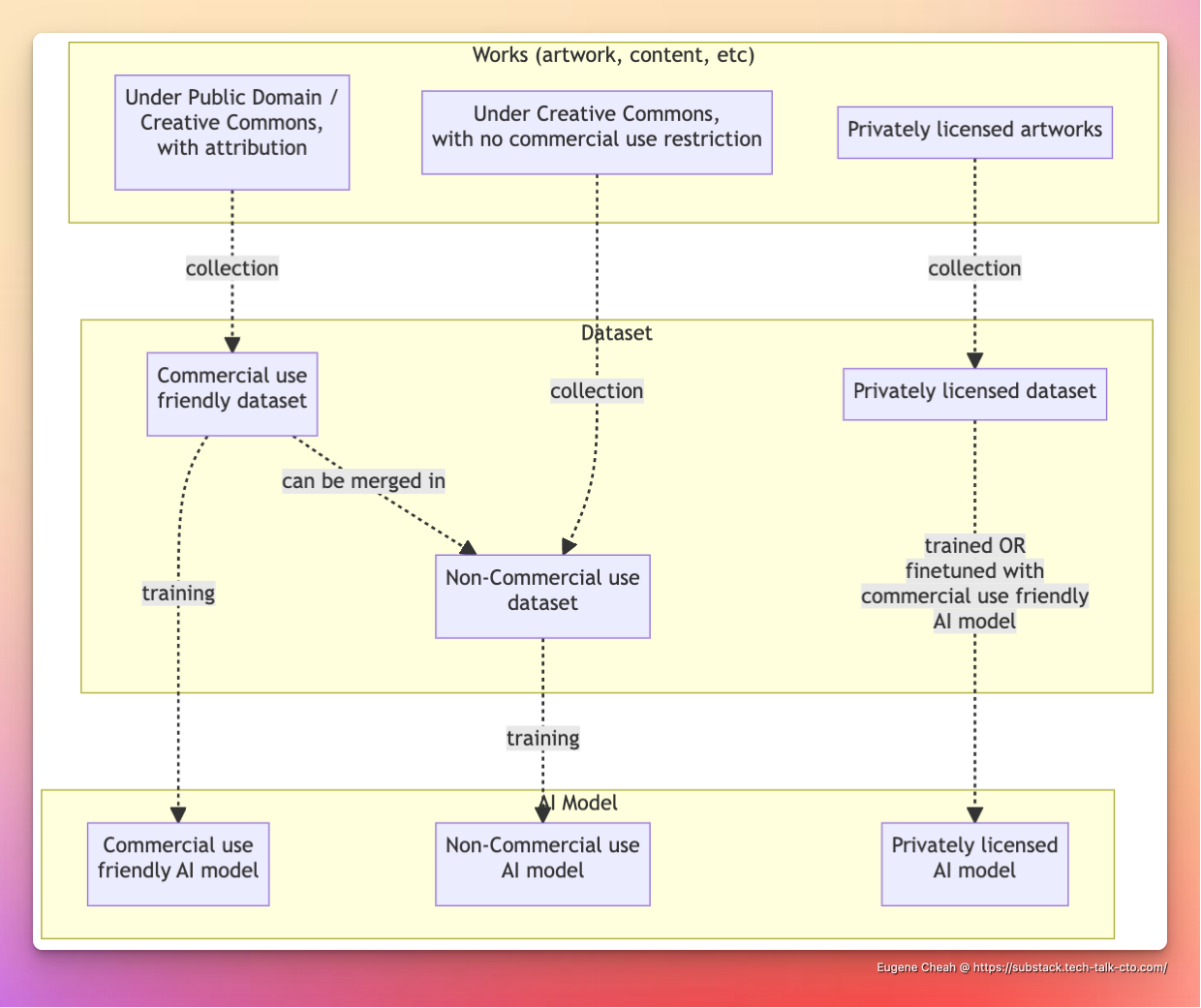
How does it work in practice? - when making AI models
By classifying, downstream datasets, and AI models, as derivative works of their upstream content, copyright can be respected across a chain.
This is similar to how open-source projects work in the software industry, allowing existing laws to work on each layer.
Dataset layer: Will be based on existing web-scrapping laws
AI Model layer: Because the final AI Model can be treated as "Code" (it literally can be exported as code), existing open-source laws can handle it. A clear legal path will clear the way for commercial adoption
AI Output layer: If we treat the AI model as code, with licensing restrictions that force attribution to its output, it falls into place with several existing code licensing models.
In all cases, attribution needs to be maintained up the chain.
For example, all AI models must attribute their datasets, which must in turn provide attribution for their sources.
Once this is established, there will be three major types of AI models:
Commercial use-friendly AI models, which can be used in commercial settings
- Creative Commons
BYor something similar
- Creative Commons
Non-Commercial use AI models, which inherited the various "No commercial use" restrictions from the original data
- Creative Commons
BY-NCor something similar
- Creative Commons
Privately licensed AI models, which will typically be based on a "Commercial use friendly AI model" and finetuned for specific licensed use cases
For right holders (ie. artists), who do not want any of their works to be used to train an AI model, or to be used by others as derivative work. They decide and stay in control, via the licensing terms.
For rights holders, who do allow derivative works, they get to decide if it's restricted to non-commercial uses (non-competing).
Finally, right holders, especially those with very unique styles, can sub-license their data, or AI model, and set their own terms of use. Typically as a way to commercialize their unique style.
How does it work in practice? - when using AI models
Using the AI model is more nuanced. Depending on if the AI is adding IP value, or not, there are two major categories that need to be outlined.
AI as an IP generator
The general rule of thumb is that the output would be the derivative of all three participants: the AI model, the human operator (via a prompt typically), and the input material (if any, for example, editing or redrawing an existing image).
This is because the final output would literally be a derivative of all three inputs.
If any of the three enforces a copyright clause (ie. attribution, no commercial use), so will the derivative output. If the AI model follows the Creative Commons model, and the "Human Operator" has full rights to the input, the "Human Operator" would have full rights to the output, with the attribution clause limitation (and the no-commercial clause for no-commercial use AI).
If it's just the "Human Operator" and the AI, the above structure still applies.
AI as a reduction tool
This is currently limited to the AI text model, where the AI is used in a way that does not add IP value. For example in "Short Summarization, Labeling, or Factual Extraction".
In this case, if the output has no additional content added and is simply the reduction of the input, per the user instructions, and was done so in a way that is clearly mapped to the instruction - the AI has arguably not "added any IP or context".
As such, in this case, the AI model should be treated as if it was a tool/extension of the human operator. And the output copyright should be as if the "Human Operator" performed the said instructions manually. (Need legal feedback on this segment)

Regardless of how any artist feels, AI has raised the bar
Will this stop AI from taking artist jobs?
Quite frankly, No. The bar has been raised for being an artist.
If the artist's primary job was commissioned to render artwork in a commonly known style, that is out of copyright (eg. Vincent van Gogh style) or is very common in the public domain, then this won't stop AI from taking artist jobs.
However, if the artist were to make or remix a newer style, that is unique and distinctive to them, then this prevents their new style or likeness from being copied. This allows them to commercialize and be rewarded for their style on their terms, with time entering the public domain.
Ultimately, allowing them to make a name and career for themselves, for their unique style.
Into this, strange new AI world.

Alright, what's next?
As I am neither a professional artist, lawyer, nor politician, this may just end up being a programmer screaming into the crowd. However, if this approach makes sense to you, especially if you are an artist, do feedback, forward it to as many legal friends, and start organizing a movement towards this.
For any lawyers who wish to refine this to a legal paper, please do so, reach out to me, and provide credit.
The only paper I can find exploring this angle is "AI Derivatives: the Application to the Derivative Work Right to Literary and Artistic Productions of AI Machines"
At the end of the day, I wish that we all steer in a direction where both AI and artists can work together hand in hand. Either with what's proposed, or any other alternative proposal that respects both sides.
~ Until next time 🖖 live long and prosper
Eugene Cheah @ tech-talk-cto.com
For more on how AI works by dreaming,
Originally posted on the author's substack: https://substack.tech-talk-cto.com/p/how-opensource-style-licensing-can
All Images used, with their proper attribution
Hand Stacked Coins With Justice Scale by focusonmore.com under CC BY 2.0
Race Car Photo by Abed Ismail via unsplash.com
Goals and Plans Photo by Content Pixie on Unsplash
Stop Hand Photo by Nadine Shaabana on Unsplash
Pole Vault Photo by Frans Vledder on Unsplash
Sunrise Photo by Nicole Avagliano on Unsplash


